POUR UN CONTRÔLE RÉCIPROQUE
LE CAS DE L'ANALYSE DES RÉPONSES À UNE QUESTION OUVERTE
"Quelles sont les difficultés que vous rencontrez dans votre vie étudiante ?"
La question fut posée en 1991 à environ 3000 étudiants représentatifs des quelques 24000 étudiants de l'enseignement supérieur niçois[4]. Le traitement d'une telle question ouverte posait évidemment le problème du codage : allait-on procéder à une analyse de contenu classique (par thèmes) ou bien à une analyse lexicométrique (par formes lexicales) ? En recherche, notamment appliquée, les considérations d'économie ont un poids qu'on ne saurait occulter : entre le temps passé au codage thématique manuel et l'investissement dans une saisie informatique exhaustive du corpus, la sécurité que représente l'usage d'un logiciel éprouvé pouvait faire la différence... Examinons plutôt, sur le fond, les différences essentielles, épistémologiques, entre les deux approches.
1. Analyse de contenu et analyse lexicométrique : deux manières antagonistes d'approcher le sens d'un texte ?
Il nous semble utile de rappeler deux systèmes d'oppositions qui alimentent largement les débats d'écoles ou de chapelles.
1.1. Modèles de raisonnement
On distingue classiquement deux modèles de base dans la construction progressive de la connaissance : le modèle hypothético-déductif (i) et le modèle inductif (ii).
(i) le modèle déductif fonctionne à l'instar du modus tollens : élaboration d'une hypothèse (H) dans un cadre théorique précis, dérivation de conséquences observables (C), observation effective et réfutation ou corroboration de l'hypothèse (test).
H => C si H implique C
5 C et si C n'est pas observée
------------
5 H alors H est réfutée
(ii) le modèle inductif procède à l'inverse par généralisation : l'observation (O) est première et l'on doit imaginer la ou les hypothèses (H) qui pourraient en rendre compte.
O -> H
La dérivation (->) d'hypothèse(s) obéit évidemment à des stratégies que l'on peut moins aisément rapporter à des procédures formelles.
Tester une hypothèse ou interpréter une observation sont ainsi des procédures que l'on oppose souvent :
(i) soit pour préférer la première : son cadre formel lui confèrerait des propriétés d'évidence, de rigueur, d'explication et de cumulativité ; on la dira volontiers "empirique" par opposition à la démarche interprétative (ii), "empiriste", dont le défaut majeur serait de produire des hypothèses ad hoc, voire de ne pas dépasser une simple description des observations,
(ii) soit pour préférer la seconde : libre de tout préjugé, son objectivité permettrait de rester attentif à l'inattendu et produirait des résultats de recherche plus riches que la première, souvent condamnée à une grande pauvreté descriptive et à la pétition de principe (ne recueillir que ce que l'on a mis dans l'hypothèse).
1.2. Familiarité et distanciation
Dans le champ de la recherche littéraire, l'antagonisme suivant (a/b) alimente largement les discussions d'école ou de chapelle :
(a) l'approche du sens d'un texte nécessiterait la connaissance intime de celui-ci, sa lecture approfondie, la connaissance des conditions de sa production, etc. ; elle est qualitative, intensive ; elle met en jeu une compréhension en profondeur. Le sens d'un texte dépend certes de son contexte (le complémentaire du texte dans l'ouvrage, le complémentaire de l'ouvrage dans l'oeuvre, les oeuvres des autres auteurs de l'époque, les auteurs des autres époques, les autres disciplines artistiques, etc.) mais à quelque niveau que l'on se situe c'est toujours à une expérience qualitative et insentive des oeuvres que l'on se réfère, excluant par là toute approche statisticienne, quantitative, extensive.
(b) à l'opposé, l'analyse statistique d'un ensemble de textes regroupés en corpus serait libre de tout préjugé littéraire : les régularités et typologies observées seraient indépendantes des a priori et des fausses évidences.
1.3. Relativité et intérêt pédagogique de ces oppositions
Quel statut accorder à ces couples d'oppositions ? On pourra certes avancer qu'ils ne se superposent en rien : la critique littéraire peut relever de la plus plate description paraphrastique et l'analyse lexicométrique trouver sa place dans un schéma rigoureux de test d'hypothèse. Les étapes d'élaboration inductive d'hypothèses et de leur test, bien que distinctes, s'inscrivent en fait dans un processus dialectique :
... -> observation -> hypothèse -> test de l'hypothèse -> observation -> ...
Et d'autre part, il n'existe pas de méthodes descriptives ou exploratoires en soi : le type de fonctionnalité d'une méthode dépend tout autant de ses caractéristiques formelles que de l'utilisation qui en est faite.
C'est dans cette dernière optique que nous nous proposons de comparer analyse de contenu et analyse lexicométrique et nous considérons que les oppositions recensées permettent à tout le moins une démarche expérimentale et pédagogique. Notre objectif sera de partir de positions initiales assez tranchées pour que leurs effets soit nettement différenciables.
1.4. Principes de la simulation
Nous supposerons ainsi deux situations limites :
(i) une analyse de contenu motivée par une hypothèse sociologique définie et un modèle de réponse précis,
(ii) une analyse lexicométrique résolument exploratoire.
Par construction de la question ouverte ("Quelles sont les difficultés que vous rencontrez dans votre vie étudiante ?"), le matériel dont nous disposons nous semble particulièrement approprié à une telle expérience :
- les thèmes (ou les formes lexicales) sont nécessairement de modalité négative: quand on cite l'argent, les loisirs, le temps, les professeurs, etc., c'est que des "difficultés" leurs sont forcément attachées, d'où une réduction notable des sources d'ambiguïté. Aucun étudiant ne vient vanter les mérites de ses professeurs ni ne se félicite des loisirs que sa condition lui offre : la question posée ne lui permet ni ce zèle ni cet humour !
- les réponses de chaque étudiant sont nécessairement courtes[5] et il ne peut y avoir de grandes différences entre la liste des thèmes qui les résument et le lexique qu'elles contiennent, d'où une identification plus aisée et plus pertinente des causes d'écarts malgré tout obtenus entre les deux méthodes[6].
2. Une analyse de contenu sous hypothèses
2.1. Règles de codage, modèle de réponse et logique du sujet
On suppose[7] que la représentation que l'étudiant se fait de ses propres difficultés dépend du caractère plus ou moins professionnel de la formation suivie. Il existe en effet dans l'enseignement supérieur un dimorphisme institutionnel très net entre des filières à caractère professionnel ou professionnalisant (Médecine, IUT, BTS, Ecole d'Infirmiers, Classes Préparatoires, Ecoles supérieures d'ingénieurs et de commerce) et des filières à caractère général (ou dont les débouchés sont limités, incertains ou marginaux par rapport au contenu des études : Lettres et Sciences Humaines, Droit, Sciences Economiques, Sciences, Sciences et techniques des activités physiques et sportives ; nous les appellerons les "facultés"). Les filières professionnelles se distinguent objectivement des facultés : sélection à l'entrée, encadrement renforcé, visibilité des objectifs... Or, on peut faire l'hypothèse que le contexte du chômage, la précarité de l'emploi (même pour les diplômés) est un facteur qui crée ou renforce un dimorphisme, corrélatif, des représentations. Les étudiants des formations professionnelles ne mettront pas tellement en cause les institutions en elles-mêmes mais souligneront les contradictions entres les demandes de ces institutions et les conditions objectives vécues (trop de travail, pas assez de loisirs, de temps libre, de possibilités de faire du sport, etc.), c'est-à-dire les "incompatibilités" de la vie étudiante. Plus interrogatifs et anxieux quant à leur avenir, les étudiants des formations générales s'en prendront plus volontiers aux institutions en tant que telles : faible qualité des enseignements, mauvaise organisation, manque de sociabilité, etc.
Des règles explicites de codage se déduisent d'une telle hypothèse. Soit par exemple les réponses :
(a) "Les emplois du temps sont imprévisibles."
(b) "Mauvaise organisation des emplois du temps."
(c) "Emploi du temps trop lourd."
(d) "Horaires trop chargés."
- (a) et (b) seront assimilés dans une classe d'équivalence emploi du temps, au sens du découpage temporel qualitatif (qualité négative de l'institution) alors que - (c) et (d) seront assimilés dans une classe trop de travail (incompatibilité entre la demande institutionnelle et les possibilités objectives de l'étudiant).
- "Manque d'argent pour m'installer éventuellement." sera classé dans le thème représentation de l'avenir, la séquence "Manque d'argent" étant éliminée.
La définition de telles relations d'équivalence implique évidemment un modèle du sujet (tel que défini dans les hypothèses) ainsi qu'une lecture en contexte des occurrences observées dans les réponses individuelles.
Un modèle de réponse (à la situation de questionnement) est également nécessaire au classement thématique. On est ainsi amené à éliminer du codage une importante partie du vocabulaire. Ainsi les modalités renforçant la valence d'un terme (valence nécessairement négative) ne seront pas codées : "L'administration est incompétente." équivaudra à "L'administration."
De même l'expression des conséquences d'une difficulté pourra être omise dans le codage : "Problèmes de transports, d'où pertes de temps." = "Transports.", "Trop d'heures de cours, d'où fatigue en fin de journée." = "Trop de travail.", l'idée étant qu'il est plus important d'identifier l'expression de domaines de difficultés que les arguments d'un discours justificatif. Il est certain qu'on se heurtera à des cas difficiles comme "Manque d'argent, donc gros problèmes pour les transports." qu'on hésitera à équivaloir à "Transports, d'où problèmes financiers." = "Transports.".
La difficulté de mise en oeuvre d'une telle méthode est incontestable et tient à la rigueur et à l'exhaustivité de la liste des règles d'équivalence qu'il est nécessaire de définir. En revanche, son principal avantage est justement d'expliciter l'ensemble des hypothèses qui président pour le chercheur à la levée des ambiguïtés : c'est bien là une des conceptions possibles de l'objectivité. En second lieu il est clair qu'une telle entreprise repose sur des opérations irréversibles : si une règle se révélait inapplicable à la 1000ème réponse il faudrait la modifier et recommencer le codage dès le début du fichier. On y regardera donc à deux fois avant de commencer et on prendra le temps de la réflexion. On prendra également le temps de réaliser les tests préalables qui manquent souvent aux analyses de contenu.
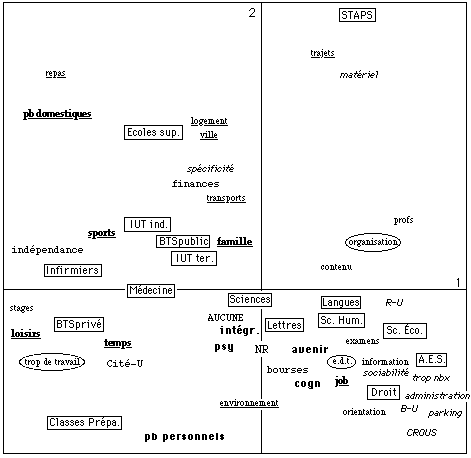
La Carte 1 (Analyse Factorielle du Tableau 1, donné en Annexe avec la liste des thèmes) résume la correspondance entre la thématique et la filière. On voit que l'hypothèse de départ est corroborée : les filières professionnelles s'opposent bien aux "facultés"[8]. Les filières professionnelles se caractérisent par un sur-emploi des thèmes de l'incompatibilité de la vie étudiante (en gras souligné : sports, loisirs, etc.[9]) alors que les "facultés" sur-emploient sans aucune exception les thèmes critiques : enseignement (contenu, professeurs, examens), administration, services, sociabilité, etc. Les positions de "trop de travail" et "emploi-du-temps" (dans les bulles) correspondent à l'opposition attendue[10]:
Carte 1. Les thèmes selon l'analyse de contenu
3. Deux exemples d'analyse lexicométrique exploratoire
Voyons a contrario ce que deviennent les correspondances relevées lorsque l'on se borne au dénombrement des mots, autre conception possible de l'objectivité.
Dès lors qu'un corpus est structurable en sous-corpus ou textes différents, il entre dans le cahier des charges de tout logiciel d'analyse lexicométrique de construire des tableaux [(formes) x (sous-corpus)] et de les soumettre aux analyses statistiques standards, dont l'Analyse Factorielle des Correspondances[11].
Mais comment définir la liste des formes ? On peut y procéder :
(i) par choix raisonné : on sélectionne, après inspection du dictionnaire, les formes qui paraissent intéressantes, par exemple en éliminant les mots outils et les formes indiquant la modalité (comme "incompétents", "absents", "nuls", "distants",... pour garder "profs", "professeurs", "enseignants")
(ii) "objectivement", par exemple en conservant toutes les formes ou les formes de fréquences supérieures à une valeur arbitraire.
3.1. De la logique du mot à "l'analyse textuelle des données statistiques"
Simulons (i). Les options possibles dans la construction des tableaux évitent bien des manipulations fastidieuses. Ainsi Hyperbase permet-il de recalculer le tableau [(formes) x (textes)] après regroupement de colonnes (textes) et/ou de lignes (formes). Diverses considérations peuvent motiver un regroupement de formes (faiblesse des effectifs de chaque forme, équivalence "évidente" de certaines formes...) mais il y a deux manières d'y procéder :
(j) a priori, en décidant de regrouper entre elles les formes qui auraient la même signification, par exemple "blé", "fric", "$", "argent", "money", "sous", subsumés par argent ou encore, bien sûr, par lemmatisation : "cher" = "chère" = "chers" = "chères", si tant est que quelqu'un parle encore de "ses chers professeurs"...
(jj) a posteriori, après inspection des proximités de formes sur une première carte factorielle, par exemple "documentation", "livres" et "bibliothèque" ou encore "professeurs" et "contact", "trajet(s)" et "déplacement(s)", etc.
Peu ou prou, les deux méthodes reprennent à leur compte l'arbitraire de codage que l'on pourrait critiquer en analyse de contenu, même si le logiciel permet une vérification par retour au contexte (concordances, etc.). Mais la seconde (jj), qui consiste à interpréter les proximités de mots pour les réunir dans des paradigmes hypothétiques voire dans des pseudo-syntagmes (syntagmes qui n'ont peut-être jamais été énoncés), réalise ce qu'on peut bien appeler (sans lapsus) une "analyse textuelle de données statistiques"[12]...
La carte factorielle ci-dessous a été établie selon un choix (i)(j), indépendamment[13] de l'analyse de contenu présentée supra. La liste est une liste de formes (p.ex. mais ="maison" ), de formes lemmatisées (p. ex. spor pour "sport(s)", "sportif(s)", "sportive(s)") ou de thèmes au sens de sous-listes de formes (par exemple soci pour "sociabilité", "relations", "individualisme", "ambiance", etc.). Nous appellerons termes ces divers éléments de la liste. Il est évident qu'on entre là dans une "logique de mots" qui n'est pas une logique de sujet : l'examen de quelques contextes ne peut que conférer une validité probabiliste aux décisions d'équivalences.
Carte 2. Carte factorielle des termes
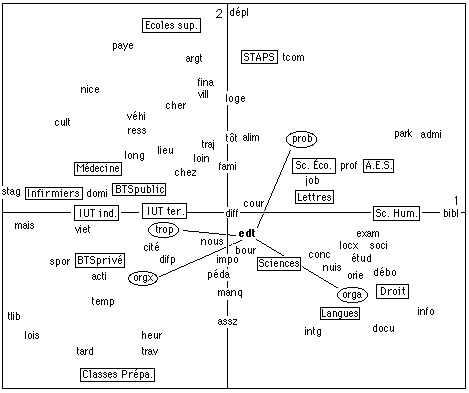
La Carte 2 présente une isomorphie évidente avec la carte précédente en ce qui concerne les filières : il ne pouvait guère en être autrement du fait de la simplicité du corpus (les réponses sont plutôt des catalogues revendicatifs) et des propriétés d'équivalence distributionnelle de l'analyse des correspondances (invariance par regroupement de lignes à profil identiques). Il n'en va pas de même pour les termes. Le terme edt ("emploi(s)-du-temps", "horaires")[14] est au centre de gravité, avec une inertie relative pratiquement nulle. Les emplois du temps feraient-ils uniformément problème dans les différentes filières ?
Termes utilisés sur la carte 2 : de haut en bas
/ dépl : les déplacements / paye : dépenser, acheter, payer, dettes /
argt : manque d'argent / fina : problèmes financiers, pécuniaires /
tcom : transports en communs / nice : ville de nice /
ville : ville, centre ville lointains / cher : cherté, coûts, prix /
loge : logement / véhi : véhicule, voiture / cult : activités culturelles / ress : ressources, salaire, etc. / tôt : matin, lever, tôt /
alim : restau-U, nourriture / park : parking, se garer /
admi : administr., secrétariat, faculté / lieu : d'études, de travail, rencontre /
traj : trajets / prob : problèmes / loin : loin, éloigné / long : longueur des trajets / chez : chez moi / fami : famille / prof : professeurs, incompétence, absence, etc. / job : profession, salariat /
stag : stages / domi : domicile / cour : cours /
diff : difficultés / bibl : bibliothèques /
mais : maison / viet : vie, étudiante / trop : trop / edt : emploi(s) du temps, horaires / exam : examens, partiels /
spor : sport, sportif / cité : cité universitaire / nous : nous /
bour : bourse / locx : locaux, matériel / soci : sociabilité /
difp : difficultés personnelles / impo : impossibilité / conc : concilier /
étus : étudiants, élèves / orgx : surcharge, accumulation, dispersion /
péda : programmes, matières / nuis : nuisances, bruit, monde, attente / débo : débouchés / temp : temps / manq : manque /
orie : orientation / orga : organisation / info : information / assz : assez /
intg : motivation, adaptation, rythme, solitude / docu : livres, manuels / lois : loisirs, distractions, sorties / heur : heure(s) / tard : tard, soir /
trav : travail universitaire /
Certainement pas. Mais les décisions de codage sont telles que l'analyste aura bien du mal à débrouiller l'écheveau qu'il a lui-même créé de toutes pièces. On a en effet :
- edt = "emploi(s)-du-temps" + "horaire(s)" (thème)
- orga = modalités de l'organisation : surcharge, dispersion, perte (thème)
- trop = "trop" (forme)
- prob = "problème(s)" (lemme)
- orga = "organisation" (lemme)
Et l'inspection des concordances montre que :
- en filières professionnelles, edt est plutôt associé à trop par "horaires trop lourds", "emploi-du-temps trop chargé", etc., et à orgx par "surcharge de l'emploi-du-temps"
- dans les facultés edt est plutôt associé à prob par "problèmes d'emplois-du-temps" et à orga par "emplois-du-temps mal organisés", d'où sa position au centre de gravité de ces 4 points, donc près du centre de gravité du nuage de points.
Un double résultat apparaît donc, que l'on peut interpréter autant comme un danger que comme une prouesse de l'analyse statistique :
- un terme (comme edt) qui est défini par une extension trop large, se rapprochera du centre de gravité. L'erreur consistera alors à négliger ce terme ou, pire, à déduire qu'il recouvre une réalité uniformément présente dans la population considérée, ce qui n'est pas le cas dans l'exemple choisi.
- si les autres termes qui lui sont liés ne sont pas eux-mêmes trop extensifs (exemples : trop, orgx, prob, orga), le terme se localisera vers leur centre de gravité, phénomène parfaitement lisible sur la carte factorielle. Et c'est sans aucune difficulté que l'analyste s'en apercevra pour autant qu'il ait consulté les concordances et les contextes relatifs au terme douteux.
3.2. Toutes les formes, rien que les formes
La reproductibilité d'une méthode est un avantage scientifique non négligeable, en termes d'objectivité comme en termes de vérifiabilité. La prise en compte exhaustive de l'ensemble des formes en donne bien sûr une triviale garantie. En pratique, on pourra se limiter aux formes de fréquences supérieures à une valeur donnée. Nous avons pris le seuil de 15 occurrences minimum dans l'analyse suivante, d'où 191 formes différentes. Nous l'avons toutefois effectuée avec désambiguïsation préalable des formes de l'emploi du temps (traits d'union), du travail (distinction entre "travail" universitaire et "travail" professionnel, codés différemment) et de l'organisation (distinction entre auto-"organisation" et "organisation" administrative, codés différemment), en conformité avec l'analyse précédente.[15]
Ici encore, la structure des proximités et des oppositions entre les filières est conservée (Carte 3).
Carte 3 : les formes lexicales les plus fréquentes (f >= 15)[16]
(sont reproduites les formes statistiquement les plus significatives)
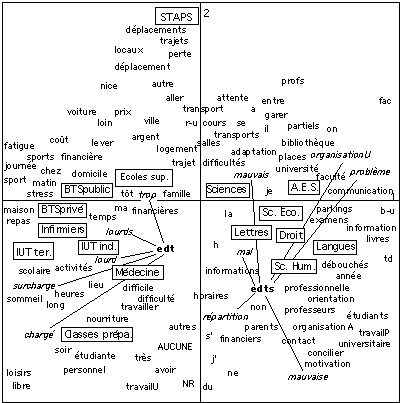
La position solitaire de STAPS est cependant à noter et rejoint la première de nos analyses. Elle résulte de difficultés et d'un vocabulaire très spécifiques à cette filière : "déplacements", "déplacement", "trajets", "locaux", "perte"[17]. Les Ecoles Supérieures de Sophia Antipolis (Valbonne) sont elles aussi dotées d'un vocabulaire spécifique : "transport", "coût", "financière", "problème", "cher", "logement". On ne les trouvera avec une forte inertie qu'en tête d'un 4ème axe factoriel.
On peut déjà constater que plus les spécificités de vocabulaire sont importantes plus les risques sont élevés d'obtenir certains facteurs qui soient déterminés par un seul texte : c'est ici le cas des axes 2 (STAPS) et 4 (Écoles supérieures). Il s'agit d'un mécanisme statistique général et le cas limite est celui d'un nuage de points sphérique, où aucun regroupement n'apparaît plus car chaque facteur correspond à un texte et un seul, situation incompatible avec l'objectif typologique.
Sur la Carte 2, le terme traj (pour "trajet" et "trajets") se situe dans la direction conjointe du STAPS et des Écoles supérieures. Sur la Carte 3, "trajets" est nettement associé à la filière STAPS tandis que les Écoles supérieures correspondent à "trajet". C'est que les étudiants de la première sont fréquemment confrontés à des déplacements divers et perçus comme anarchiques alors que pour les étudiants de la seconde c'est le trajet entre leur école et leur domicile qui est en cause. Doit-on en conclure que la Carte 2 est erronée ? Pas nécessairement car il est bien exact que les deux filières ont en commun des problèmes de parcours et de distances. Mais ils ne sont pas de même nature et sont ressentis différemment, plutôt en terme de temps perdu pour les uns, plutôt en termes d'argent perdu pour les autres. Il reste que la position du STAPS, quelle que soit l'analyse, est toujours excentrique, orthogonale à l'axe principal, c'est-à-dire indépendante de l'opposition principale entre filières professionnelles et filières généralistes. Cette remarquable invariance pourra conduire le sociologue à réviser en partie ses hypothèses sur cette filière.
Nous avions vu que de la carte 1 à la carte 2, le regroupement en un seul terme des formes relatives au temps contraint faisait problème. Qu'en est-il maintenant, ces formes étant complètement distinguées en l'"emploi-du-temps", les "emplois-du-temps", les "horaires". L'analyse factorielle exhibe une nette différenciation dans l'usage du nombre, qui apparaissait déjà en 3.1. par inspection des concordances. Les formes au pluriel ("emplois-du-temps", "horaires") sont plutôt caractéristiques des facultés alors que la forme au singulier "emploi-du-temps" est plutôt typique des filières professionnelles. Les formes au pluriel désignent les productions de l'administration alors que la forme au singulier renvoie à l'essence de la situation de celui qui est dévoré par le temps. Hypothèse confirmée par un examen des concordances les plus fréquentes (cf. liaisons indiquées sur la carte 3) :
- "emplois-du-temps" concordant plutôt avec :
"répartition", "mauvais", "mal", "organisation", "problèmes", "mauvaise"
- "emploi-du-temps" concordant plutôt avec :
"chargé","lourd","surcharge","lourds","trop".
Il est clair également que l'étudiant de faculté est davantage confronté à une multiplicité d'emplois du temps (en Lettres et Sciences Humaines en particulier, avec les problèmes liés au choix des options) alors que l'étudiant de filière professionnelle, davantage pris en charge, évolue dans un système moins ouvert.
Au total, il semble instructif de présenter une vue synoptique des positionnements de l'emploi du temps selon la méthode utilisée :
Carte 1 : les thèmes

Carte 2 : les termes
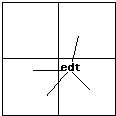
Carte 3 : les formes

L'analyse de contenu permet de rapporter à des thèmes différents les occurrences de l'emploi du temps (et des horaires). Les unes sont associées à la charge de travail, les autres à la mauvaise qualité des prestations admini-stratives.
La séparation des deux thèmes est très nette mais pourrait être imputée à l'arbitraire de codage.
L'analyse par termes, c'est-à-dire par définition hors contexte de classes d'équivalence entre for-mes lexicales, assigne l'emploi du temps au centre de gravité, terme devenu trop extensif pour correspondre à une catégorie de filières plutôt qu'à une autre.
L'analyse par formes lexicales oppose les deux formes diffé-rentes de l'emploi du temps (singulier : edt et pluriel : edts) sans intervention aucune de l'analyste. L'opposition entre ces deux formes confirme les décisions de codages de l'analyste de contenu.
4. Pour un étalonnage systématique des techniques de dénombre- ment en analyse de discours
L'impression qui résulte des essais réalisés est duelle, selon que l'objectif est de classifier les filières ou bien de classifier les réponses.
4.1. Invariance de la typologie des "textes"
En ce qui concerne les filières, on ne peut qu'être surpris de l'invariance de la classification obtenue, quelle que soit l'option méthodologique utilisée. L'explication tient sans doute à la simplicité du corpus et au mode quasi obligé de réponse sous forme de cahier de doléances. Au total, changer d'option revient grosso modo à faire varier la finesse de la partition de la liste du cahier. Lorsque la finesse de la partition diminue, les anciens points (formes ou thèmes) sont remplacés par leurs centres de gravité (termes), ce qui affecte finalement peu la disposition des filières. Pour différencier nettement les résultats obtenus à partir des formes et des thèmes, il faudrait sans doute travailler sur des entretiens, de telle sorte que la définition des thèmes puisse avoir un lien beaucoup plus lâche avec le lexique. Des expériences systématiques sur ce sujet seront certainement instructives et de grosses surprises attendront sans doute le chercheur qui comparera, sur des textes longs et complexes, les output d'analyses de contenu et d'analyses lexicométriques.
4.2. Variation de la typologie des réponses
L'exemple du temps scolaire contraint montre bien les risques d'interprétation hâtive des positions de détail des éléments de réponses, thèmes, termes ou formes. Sans prétendre à la généralité, il semble qu'on puisse avancer quelques règles de prudence minimale :
* Règle 1 : éviter si possible l'option lexicométrique par regroupement de formes (3.1.), méthode bâtarde entre l'analyse de contenu et l'analyse lexicométrique exhaustive ou quasi exhaustive (avec seuil ou autre critère).
* Règle 2 : doubler une analyse par une autre, au moins à titre de test sur un échantillon limité, soit pour faire état de congruences soit pour faire état de divergences interprétables. On pourra ainsi valider une analyse de contenu par l'étude, indépendante, des régularités statistiques lexicales (concordances, analyse factorielle) et inversement.
* Règle 3 : se reporter systématiquement au contexte, en particulier en cas de tentation de lire des syntagmes sur les cartes factorielles (cf. exemple de la "perte de temps").
* Règle 4 : étalonner la méthode retenue, c'est-à-dire observer comment elle réagit à des variations opérées sur les paramètres qui la définissent : technique de codage en analyse de contenu (2), niveau de finesse dans les regroupements (3.1.), choix du seuil (3.2.), etc.
* Règle 5 : calibrer la méthode, c'est-à-dire observer les types de régularités qu'elle semble apte ou non à mettre en évidence.
Les expériences que nous avons présentées sont autant de simulations de modèles d'analyses portant sur un corpus réel. Une expérimentation en quelque sorte inverse est possible : pourquoi ne pas construire des corpus artificiels, générés à partir de modèles de discours bien choisis (axiomes) et faire jouer ensuite la "concurrence" ? On rechercherait ainsi l'aptitude à déceler les axiomes du modèle et on essaierait d'en dériver des règles générales sur la supériorité, l'infériorité ou la complémentarité des différentes approches selon le type de modèle sous-jacent à retrouver.
ANNEXE
Ecoles Prépa IUT IUT BTS BTS Infir STAPS
Sup. ind ter privé public miers
non réponse (NR) 49 74 38 47 39 52 27 10
AUCUNE 7 8 9 9 0 4 1 3
profs 1 0 0 2 3 3 1 12
contenupb. 14 10 21 32 12 50 10 60
domestiques
finances 48 3 33 21 26 42 26 33
indépendanceavenir 21 00 27 01 21 02 20 01
ANNEXE
(suite)
AES Droit Sc. Scien Méde Sc. Let- Lan-
Eco ces cine Hum. tres gues
non réponse (NR) 37 101 75 98 90 95 99 77
AUCUNE 2 11 2 11 13 13 9 11
profs 10 10 12 5 6 14 5 15
contenupb. 70 70 120 80 100 40 30 70
domestiques
finances 24 21 28 32 66 57 49 37
indépendanceavenir 05 110 00 04 62 110 04 06
Cf. Michel NOVI.- << Les difficultés de la vie étudiante, analyse lexicométrique d'une question ouverte >> in Alain CHENU, Valérie ERLICH, Alain FRICKEY, Michel NOVI: La vie étudiante dans les Alpes-Maritimes. Modes de vie et espace urbain, Rapport pour le Ministère de l'Équipement.- Laboratoire de Sociologie de l'Université de Nice-Sophia Antipolis (GERM).- 1993.
[5] Elles comprennent de 1 à 49 mots. Voici les réponses les plus courtes : "Moi.", "Fric.","Bruit.", "Temps.", "Stress.", "Argent.", "Trajet.". La réponse la plus longue est : "Cité universitaire trop éloignée de la Fac ; le repas de midi au restau-U souvent infect et peu varié ; trop de monde à la bibliothèque ; les emplois du temps ne tiennent pas compte du temps pour manger à midi (parfois une heure de queue), et mal répartis dans la semaine."
[6] Les réponses-catalogue, p. ex. "Argent, logement, repas, transport.", sont fréquentes et n'autorisent que très peu d'écart entre analyse lexicale et analyse thématique.
[7] Les hypothèses utilisées, quoique plausibles, peuvent être tenues pour arbitraires dans cette approche. Notre argument est simplement que des règles explicites de codage résultent nécessairement des hypothèses. Pour d'autres hypothèses, d'autres règles de codage.
[8] La position intermédiaire des Sciences traduit l'évolution professionnalisante de ce secteur, notamment vers les métiers de l'informatique industrielle ou de gestion. On peut penser que la position excentrique du STAPS (sc. et techniques des activités physiques et sportives) est due conjoncturellement à la très faible intégration de cette jeune formation dans le tissu universitaire, obligée de fonctionner sans locaux propres : l'exaspération des étudiants du STAPS la positionne alors d'après un très fort taux de réponse et une critique acerbe de leur institution.
[9] Exception avec "job" : les études difficilement conciliables avec une activité professionnelle sont plutôt le fait des étudiants des facultés. Leurs plus faibles contraintes leurs permettent en théorie l'exercice d'un travail rémunéré.
[10] On pouvait s'attendre à trouver côté faculté les problèmes d'ego au sens strict (non liés aux exigences des institutions). Mais l'expression des problèmes psychologiques et personnels est également caractéristique des élèves des classes préparatoires. La position intermédiaire du thème "psy" est due également à un choix de codage ; y ont été classées les séquences relatives à la motivation dont le sens diffère certainement selon le caractère plus ou moins contraignant de la formation.
[11] Ce dont se charge parfaitement Hyperbase, logiciel écrit par Etienne BRUNET et que nous avons utilisé ici.
[12] "L'analyse textuelle des données statistiques" (au lieu de "L'analyse statistique des données textuelles") fut le titre annoncé pendant quelques temps pour les Secondes Journées Internationales d'Analyse Statistique des Données Textuelles, Montpellier, 1993. Le lapsus fut bien vite corrigé mais il reste possible de lui trouver une application. Ainsi, poser une équivalence de sens d'après une correspondance statistique, c'est un peu comme si on considérait le contenu d'une carte factorielle comme un texte plus simple à lire !...
[13] Aussi indépendamment que possible, l'ensemble des analyses présentées ici ayant été réalisées par l'auteur.
[14] La désambiguïsation lors de la saisie est caractéristique de ce type d'approche quelque peu hybride et cette simulation y sacrifie pour l'emploi-du-temps ou les emplois-du-temps (saisis avec des traits d'unions), le travail (trav= travail scolaire, job=travail professionnel), et l'organisation (orga = inorganisation de l'administration, les problèmes d'auto-organisation étant rangés dans dans difp, difficultés personnelles).
[15] Opération indispensable à la comparaison avec les résultats précédents. Sans cette désambiguïsation ces items se seraient positionnés vers le centre de gravité, phénomène ici sans intérêt.
[16] Sur le graphique edt représente la forme "emploi-du-temps", edts la forme "emplois-du-temps" ; on a souligné les formes qui expliquent la différenciation de ces deux références. On a codé, dans le corpus : organisationU, la forme "organisation" au sens administratif (mauvaise organisation des emplois-du-temps, organisation déplorable de l'administration,...) ; organisationA, la même forme au sens d'auto-organisation (difficultés d'adaptation et manque d'organisation). De même, travailU est relatif au travail universitaire (trop de travail) ; travailP au travail professionnel (difficile de concilier travail et études).
[17] Il s'agit de perte de temps, "temps" étant plutôt accaparé sur les cartes par les étudiants dont les horaires sont lourdement chargés et qui se situent plutôt dans la cadran opposé. On voit bien ici qu'il ne faut pas espérer lire systématiquement des syntagmes sur les cartes factorielles.