Sommaire
Les spécificités d'un texte ou d'un corpus
Le programme SPECIF relève ce qui est spécifique dans le vocabulaire
du texte qu'on lui soumet. Il a besoin de deux série de données.
L'une est fournie par FRANTEXT: c'est la liste alphabétique des formes
employées dans le texte, avec indication de la fréquence de
chacune. L'autre est un fichier de référence auquel on compare
la liste précédente. Quoique issu également de FRANTEXT,
ce fichier est à demeure dans le présent dossier où
il tient une place non négligeable (11 Mo). Il est conçu de
telle façon qu'il permet de rapprocher les deux termes de la comparaison,
et d'adapter le calcul à l'époque (4 siècles ont été
distingués) et au genre (littéraire ou technique). En croisant
ces deux variables, le fichier de référence permet de choisir
parmi 13 combinaisons celle qui convient le mieux au texte considéré.
On compare ainsi ce qui est comparable et ce qui relève du même
état de langue et du même genre.
On s'adressera à FRANTEXT, en utilisant INTERNET, le réseau
WEB, et l'outil de communication NETSCAPE. On suppose bien entendu que l'utilisateur
a acquis le droit d'entrée qui donne accès à FRANTEXT.
Les phases initiales de la procédure sont les mêmes que dans
le programme Chrono, où on les trouvera détaillées.
1 - Solliciter par un clic le bouton Frantext, qui fait appel à NETSCAPE.
2 - Cliquer sur l'ancre FRANTEXT qui contient l'adresse réelle de
la base. On est alors mis en liaison avec le serveur de FRANTEXT qui envoie
une page d'accueil.
3 - Solliciter le bouton "ACTIVATION DE FRANTEXT" qui conduit
au menu principal.
4 - Procéder d'abord à une "Sélection bibliographique"
(3e ligne du menu), avant de retourner au menu principal. Prendre garde
à choisir un corpus limité, par exemple un texte, un auteur,
ou un ensemble de textes obéissant aux mêmes critères
de date ou de genre. On doit prendre conscience que le nombre de formes
(et donc de lignes dans le fichier résultat) peut atteindre la centaine
de milliers, si le sous-corpus s'étend sur un siècle entier.
Néanmoins FRANTEXT n'a pas prévu de limitations et il est
possible de solliciter d'un coup tout le vocabulaire des Mémoires
d'Outre-tombe ou de la Recherche du temps perdu. En une telle
situation, il est préférable de disposer d'une liaison suffisamment
rapide et sûre (un modem à 28800 bauds est alors conseillé,
ou mieux encore un accès direct à Internet).
5 - Choisir l'item "Calculs des fréquences" (8e ligne)
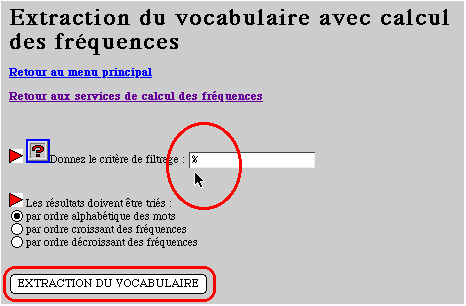
6 - Choisir l'item 3 "Extraction du vocabulaire avec calcul de fréquences"
(première ligne)

7 - Reste à remplir le formulaire ci-dessous, qui est fort simple
si l'on sait que le critère de filtrage est le caractère %.
Quand ce caractère précède une chaîne de caractères,
il permet d'isoler un suffixe. Quand il suit cette chaîne, il sélectionne
un préfixe ou un radical. Employé à chaque bout de
la chaîne il provoque une troncature dans les deux sens et retient
tous les mots qui contiennent la chaîne. Enfin, employé seul,
il ne filtre plus rien du tout et laisse passer tous les mots. C'est l'option
qui convient ici. Le tri par défaut (ordre alphabétique) convient
aussi.
Terminer en activant le bouton EXTRACTION DU VOCABULAIRE.
8 - Quand le résultat est obtenu, une longue liste apparaît
sur l'écran. Sauvegarder cette liste alphabétique, grâce
à la fonction SAVE AS de NETSCAPE, en donnant au fichier le nom VOCDAT
(dans la version PC, ce nom n'est pas obligatoire).
9 - On peut alors abandonner FRANTEXT et NETSCAPE et solliciter le bouton
SPECIF de la base.
10 - Un dialogue est instauré qui propose un choix parmi les corpus
de référence. Dans la version PC, on peut sélectionner
la date de départ et celle d'arrivée dans le corpus littéraire
de Frantext. La sélection fait en outre intervenir le genre dans
la version Mac, qui propose le dialogue suivant:

Dans la version Mac, on est amené à préciser les limites
basses pour la fréquence absolue et le seuil de l'écart réduit,
afin de diminuer ou augmenter la masse ou la spécificité de
la liste obtenue. Cela se fait automatiquement dans la version PC, eu égard
à l'étendue du texte traité. Les résultats apparaissent
sur l'écran au fil du traitement,
Sommaire
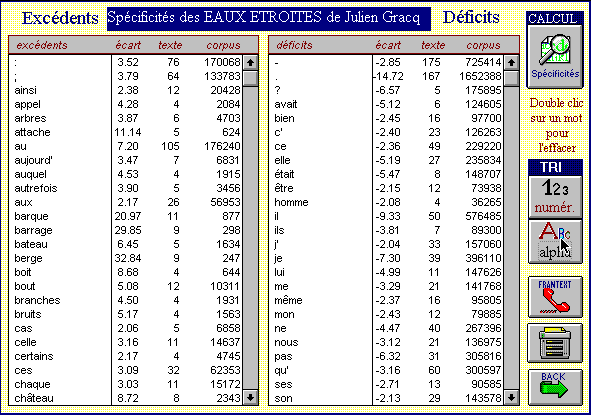
10 - Voici comment se présentent les résultats dans la version
PC. Les mots spécifiques du texte considéré (il s'agit
ici des Eaux Étroites de Julien Gracq) sont ordonnés par ordre
de spécificité décroissante (c'est-à-dire en
ordre décroissant des écarts réduits). Voir l'exemple
ci-dessous.
Spécificités. Ordre hiérarchique (version PC)
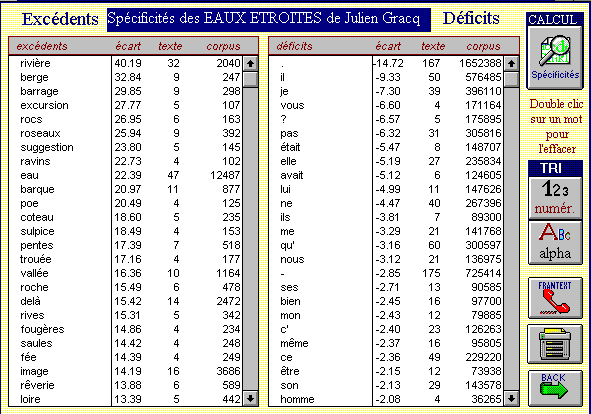
En activant le bouton de tri ALPHA on peut faire apparaître l'ordre
alphabétique (le bouton NUMER produit l'effet inverse). Dans les
deux présentations, excédents et déficits sont juxtaposés.
Spécificités. ordre alphabétique (version PC)
La version MAC
Dans la version Mac, les résultats se présentent sous deux
formes, soit alphabétique, soit hiérarchique, dans deux fichiers
séparés qu'on peut visualiser en actionnant la fonction Editer.
Noter que le bouton Editer exige le maintien de la pression sur le
bouton de la souris, afin de développer le menu Pop Up où
sont proposés les fichiers à lire. Ceux qui sont issus du présent
traitement ont pour nom: SPECIFALPHA et SPECIFTRIE. L'un et l'autre détaillent
le vocabulaire négatif après le positif. Mais deux autres
fichiers POSIT et NEGAT sont aussi générés où
l'on peut observer les excédents et les déficits.
Voici un exemple de la liste alphabétique:
Spécificités positives
fréquence > 5 écart réduit > 3
Corpus de référence : Littérature du XXe siècle
Texte Corpus Mot Écart
11 791 barque 20.3
9 246 barrage 30.3
9 174 berge 36.2
12 8034 bout 5.5
108 217788 dans 3.6
556 1102892 de 8.6
7 1272 domaine 9.8
121 178385 du 7.4
47 10002 eau 23.2
24 24997 entre 5.1
23 27906 fois 4.2
8 5416 font 4.4
6 633 glisse 12.3
7 3835 guère 4.9
14 17262 ici 3.2
16 3262 image 13.9
7 1813 jaune 8.0
241 472803 l' 5.8
368 677049 la 8.4
247 567772 le 3.4
7 6758 lieu 3.0
12 7594 long 5.7
10 9295 nom 3.7
8 5825 oeil 4.2
8 6375 ombre 3.9
43 62942 où 4.4
6 1593 paysage 7.3
Exemple correspondant de la liste hiérarchique:
Spécificités positives
fréquence > 5 écart réduit > 3
Corpus de référence: Littérature du XX siècle
Texte Corpus Mot Écart
32 1770 rivière 39.8
9 174 berge 36.2
9 246 barrage 30.3
6 151 rocs 25.8
47 10002 eau 23.2
11 791 barque 20.3
6 434 roche 15.0
16 3262 image 13.9
9 1304 promenade 12.6
6 633 glisse 12.3
7 1272 domaine 9.8
556 1102892 de 8.6
368 677049 la 8.4
7 1806 pont 8.0
Sommaire